Nederlands
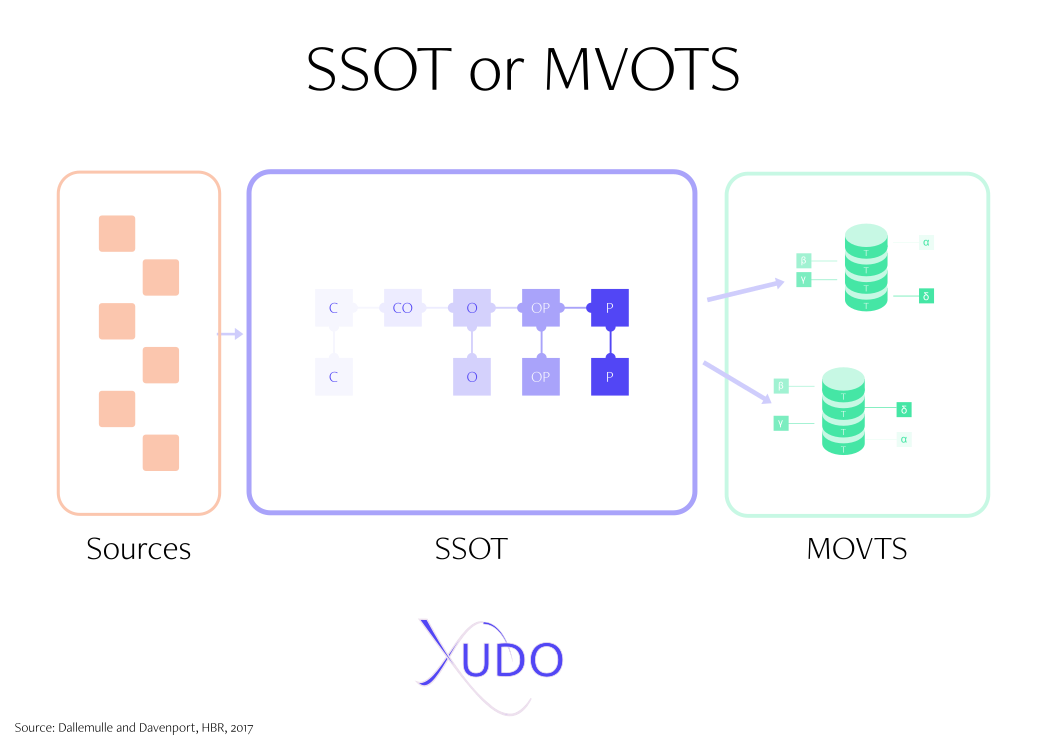
Al jaren probeer ik een single source of the truth (SSOT) te bouwen. Nu lees ik in "What's your data strategy" over MVOTs architectuur: multiple versions of the truth. Maar wacht even, was dit niet precies wat we probeerden uit te roeien? Laten we eens kijken.
Eerst onderscheiden Dallemulle en Davenport tussen data en informatie. Volgens Peter Drucker is informatie 'data begiftigd met relevantie en doel'. Het is alleen wanneer je ruwe data in context plaatst dat je informatie krijgt die beslissingen ondersteunt.
Je kunt bijvoorbeeld verkoopcijfers per productgroep en regio vergelijken met de verkoop van vorig jaar. Dit geeft je informatie waarmee je je business strategie kunt opvolgen. De ruwe data in deze analyse kunnen miljoenen kassabonnen zijn. Die zijn moeilijk te interpreteren zonder ze te parsen, sorteren of verrijken.
Veel organisaties beginnen met een top-down, gecentraliseerde, controle-georiënteerde architectuur. Deze aanpak is effectief voor het standaardiseren van enterprise data en is noodzakelijk om de data veilig en compliant te houden. Maar dit soort data management kan flexibiliteit belemmeren. Dit maakt het moeilijker om het om te zetten in uitvoerbare informatie.
MVOTs.
Gekoppeld aan deze SSOT heb je een meer flexibele manier nodig om data te gebruiken: MVOTs. Ze zijn het resultaat van business-specifieke transformaties van de data naar relevante en doelgerichte informatie. Informatie die je toespitst op verschillende contexten voor verschillende delen van de business.
Bijvoorbeeld een klant kan verschillende dingen betekenen voor verschillende afdelingen in je organisatie:
Alle data gerelateerd aan de klant leeft in de SSOT, maar je creëert MVOTs voor de verschillende afdelingen om aan hun specifieke behoeften te voldoen. Maar waarom dan, proberen we in de eerste plaats many versions of the truth uit te roeien? De many versions of the truth die we soms vinden bij onze klanten zijn niet precies gebaseerd op een SSOT. De MVOTs bij onze klanten bestaan niet alleen op het informatieniveau, maar ook op het data niveau.
Elke project manager heeft haar eigen excel met timesheets, milestones en deliverables. Dus er is geen gereguleerde SSOT op het data niveau die data bevat in lijn met bedrijfsbrede definities. Dit beperkt de mogelijkheid om projecten met elkaar te vergelijken. De klant krijgt meer of minder gefactureerd afhankelijk van de interpretatie van de timesheets. Data bestaat op verschillende detailniveaus tussen projecten, enzovoort.
Hoe los je dit op?
De database van deze software bevat de SSOT over projecten op het data niveau. Nu kun je beginnen met het bouwen van MVOTs gebaseerd op deze data. Verschillende mensen in de organisatie hebben verschillende informatie nodig om beslissingen te nemen. De project manager heeft alle details nodig om de dagelijkse activiteiten te managen. Maar management heeft alleen een paar key figures over het project nodig. De data zal hetzelfde zijn, maar de context waarin je de data presenteert zal worden toegespitst op de behoeften van de eindgebruiker.
Kortom: SSOT werkt op het data niveau, MVOTs gebruiken de data in de SSOT om het management van informatie te ondersteunen.
Ik help je uitzoeken welke conceptuele data modellen geschikt zijn om je verschillende business cases te ondersteunen. Enerzijds beginnen we vanuit alle beschikbare data om te zien hoe we het kunnen opslaan op een efficiënte, toegankelijke, uitbreidbare en veilige manier: de SSOT. Anderzijds interviewen we business stakeholders om erachter te komen hoe data beslissingen en acties kan ondersteunen om hun business vooruit te stuwen: een van de MVOTs.
Al jaren probeer ik een single source of the truth (SSOT) te bouwen. Nu lees ik over een MVOTs architectuur: multiple versions of the truth.
